Statistical models applied to tricot data
Kauê de Sousa, Joost van Heerwaarden, Hugo Dorado
Introduction
The tricot data consist primarily of rankings provided by farmers, but can also include numeric and continuous measurements such as yield, plant density, disease incidence, or days to maturity. Because the core of tricot relies on comparative evaluation, statistical models that work naturally with relative rather than absolute performance are required. For ranking data, tricot analyses rely primarily on the Plackett–Luce (PL) model (Luce, 1959; Plackett, 1975). This probabilistic model, derived from Luce's Choice Axiom, estimates the probability that an item (e.g. a crop variety) is preferred over others within a set. Each item is assigned a latent parameter often referred to as its "worth" or ability, which reflects its expected performance relative to alternatives.
The PL model has been widely used in fields where choices are made from sets of alternatives, including sports rankings, comparative judgement exercises (Chambers & Cunningham, 2022; Donovan et al., 2025), consumer preference studies (Olaosebikan et al., 2023), and crop variety selection (van Etten et al., 2019). Ranking methods in revealed-choice experiments are rapid, locally adaptable, and cognitively intuitive for respondents, requiring little calibration or training (Coe, 2002). This makes them particularly well suited for decentralized, farmer-led experimentation at scale.
In tricot, farmers typically compare three varieties per trait in an incomplete block design. The PL model is especially appropriate for this structure, as it accommodates partial rankings and comparisons among subsets of all tested varieties. This allows the aggregation of thousands of small, farmer-managed trials into a single coherent statistical analysis. For a full ranking of multiple items, the model expresses the probability of observing a specific order as a product of conditional choice probabilities. In the tricot context, this means that each farmer's ranking contributes information about relative performance, even though each farmer only evaluates a small subset of varieties.
Key advantages of the PL framework for tricot include:
- Ability to handle incomplete and unbalanced designs
- Direct modeling of ordinal (ranking) data
- Straightforward interpretation of relative performance
- Compatibility with covariates and hierarchical extensions
The estimated worth parameters can be transformed into probabilities of outperforming other varieties or into expected ranks, which are highly intuitive for breeders, extension agents, and decision makers.
Modelling heterogeneity using covariates and recursive partitioning
Farmer evaluations are influenced by environmental conditions, management practices, and socioeconomic context. To account for this heterogeneity, the PL model can be extended with covariates. One widely used approach in tricot is model-based recursive partitioning (Strobl et al., 2011). This method identifies subgroups in the data using binary splits based on environmental or socio-economic variables (e.g. rainfall, temperature, soil type, gender of farmer). Within each subgroup, a separate PL model is estimated. The result is a Plackett–Luce tree, which reveals how variety performance changes across contexts and helps define Target Populations of Environments (TPEs) (Figure 1). A TPE is a relatively uniform group of crop production environments (where and how the crop is grown). This approach has proven especially useful for identifying genotype × environment (G×E) interactions (e.g. local adaptations) under real farm conditions, supporting context-specific variety recommendations (van Etten et al., 2019).
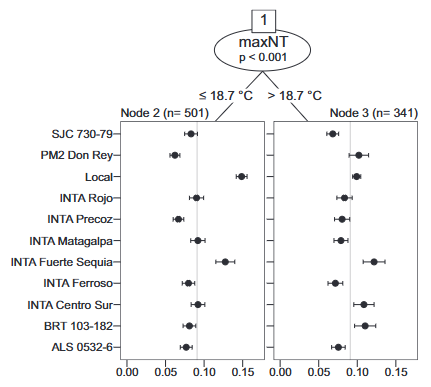
Figure 1. Plackett–Luce tree of tricot trial data and associated climatic data for common bean in Nicaragua. The horizontal axis of each panel is the probability of winning of varieties. In this case, the model selected maxNT, the maximum night temperature during the vegetative and flowering periods, as the covariate. From van Etten et al. (2019).
More recently, developments in Plackett–Luce regression allow the inclusion of linear covariates directly in the model (Alamu et al., 2023; Kang et al., 2025; Turner et al., 2020). This enables:
- Modelling of environmental gradients rather than discrete groups
- Inclusion of option-level covariates (e.g. trait data, genomic data, food lab data)
- More continuous representations of performance variation across environments
These advances bring tricot analysis closer to mainstream quantitative genetics and breeding analytics.
Analysing continous data
Although rankings are central in tricot, many trials also collect quantitative measurements such as yield or disease scores (Nabateregga et al., 2025). These data are typically analysed using linear mixed-effects models (LMMs) or generalized linear mixed models (GLMMs).
Mixed models allow partitioning of variation into components attributable to:
- Variety (genotype)
- Environment
- Farmer or location
- Residual error
They also support estimation of heritability, variance components, and genotype × environment interactions. When tricot trials include both ranking and quantitative data, analyses can be conducted in parallel and later integrated at the interpretation stage. Research is ongoing into joint modelling frameworks that combine ordinal and continuous data within a single statistical structure (Dorado-Betancourt et al., 2026).
Linking tricot with climate and environmental data
A major innovation in tricot analysis has been the integration of seasonal climate data, and other spatial covariates. Van Etten et al. (2019) demonstrated how PL models combined with climate covariates and cross-validation can produce locally specific variety recommendations. This approach allows:
- Identification of environmental drivers of variety performance
- Prediction of performance in new locations
- Development of climate-informed decision support tools
This integration is especially important under increasing climate variability, where static recommendations are insufficient.
Data synthesis across trials
Another major development is the rank-based synthesis of data across multiple trials (Brown et al., 2020). Because the PL model works with relative performance, it allows the combination of datasets from different years, locations, and experimental conditions—even when absolute measurements are not comparable. This is particularly promising for tricot, as it enables:
- Meta-analysis of decentralized trials
- Increased statistical power through aggregation
- Reuse of legacy or small-scale datasets
- Standardized data formats and open data sharing will further increase the value of such synthesis efforts, creating cumulative knowledge across projects and regions.
- Integration of genomic and biological information
In an important extension of the PL framework, de Sousa et al. (2021) incorporated genomic relatedness among varieties as a covariance structure within the model. This increased predictive accuracy, demonstrating that combining farmer evaluations with genomic information can improve selection decisions. This approach opens the door to:
- Decentralized genomic selection
- Testing genetically diverse materials under farmer management
- Better representation of G×E interactions in breeding pipelines
Such methods help bridge participatory research and advanced quantitative genetics.
From rankings to breeding decisions
Breeding programs are often interested in the probability that a new variety outperforms current standards, rather than in exact yield differences. Ranking-based analyses are well suited for this, as PL model outputs can be expressed as probabilities of superiority (Eskridge & Mumm, 1992). This aligns closely with modern breeding strategies that focus on product replacement and incremental gains (Cobb et al., 2019).
Tricot thus provides an efficient way to generate early-stage evidence about the likelihood that a candidate variety will succeed under farmer conditions.
Integrating on-farm and on-station data or lab data
A major challenge (and opportunity) in decentralized variety testing is the integration of on-farm and on-station datasets to support breeding decisions and biological interpretation of farmer preferences. On-station trials, conducted under controlled and replicated conditions, produce precise phenotypic measurements and genotypic estimates (e.g. yield, disease scores, physiological traits) that are essential for breeding decisions. In contrast, on-farm trials provide real-world performance assessments that incorporate the full complexity of farmer management, socio-economic context, and micro-environmental variation.
Kang et al. (2025) demonstrate a concrete example of such integration in potato trials in Rwanda. In this study, genotypic values estimated from on-station trials were incorporated as item covariates in the statistical model analysing farmers' tricot rankings. This strategy allowed the researchers to assess how biological measurements captured in controlled environments influence farmers' relative evaluations. Providing a richer understanding of variety performance across scales and can directly inform breeding decisions on trait prioritization and advancement in breeding pipelines.
Similarly, Alamu et al. (2023) have pioneered the use of item covariates derived from instrumental laboratory data (i.e. color, texture, hardness) in Plackett–Luce regressions, not just to explain consumers' preferences on gari (a cassava sub-product) but also to integrate biological and consumer preference data into a unified framework.
While not always focused on yield traits per se, these methods showcase how external measurements from controlled settings (e.g., instrumental sensory traits) can be used analytically alongside ranking data from decentralized trials.
Integrating on-station data into on-farm analyses can significantly enhance model robustness and interpretability. For example, item covariate models (e.g. Plackett–Luce regression with traits or genotypic values) allow the effects of measured biological traits to be directly estimated on the worth parameters used in ranking analyses.
These models effectively combine absolute performance metrics from station settings with relative performance evaluations from on-farm environments. From a breeding perspective, this integration supports a two-level modelling strategy:
- Predict genetic value and trait responses under controlled conditions, and
- Translate these predictions into expected performance under farmer conditions and diverse environments.
This strategy reflects a growing trend in crop improvement research where data from diverse sources (e.g. farm trials, climate data, genomic estimates) are systematically combined to support decision-making at both breeding and deployment stages (van Etten et al., 2023).
Future directions for integrated data analysis
From a data analysis perspective, integrating on-farm and on-station data opens important opportunities to strengthen the role of decentralised trials within breeding pipelines. A key direction is the development of multi-level models that jointly analyse ranking data from on-farm trials and quantitative trait measurements from on-station experiments. Recent work shows that ranking-based estimates of genotypic performance can be placed on an underlying continuous scale and then used in mixed-model frameworks similar to those applied in conventional quantitative genetics (Dorado-Betancourt et al., 2026).
Extending these approaches to multi-environment and multi-year datasets will allow more robust estimation of genotypic performance and variability under farmer conditions. Another priority is the integration of environmental covariates into performance models. Linking on-farm results with weather, soil, and management data enables context-specific interpretation of variety performance and supports the definition of Target Populations of Environments. Data-driven breeding frameworks emphasize that combining trial data with environmental characterization improves both representativeness and predictive power (van Etten et al., 2023).
Future analysis will also benefit from multi-trait modelling. Farmers evaluate varieties holistically, and studies of participatory trials show that preferences often reflect combinations of agronomic and end-use traits that differ across farmer segments (Voss et al., 2025). Statistical frameworks that allow simultaneous analysis of multiple traits, whether measured on-station or from on-farm rankings, will better capture these complex performance profiles.
Finally, there is growing scope for data-driven approaches that combine ranking data, quantitative measurements, and genomic or trait covariates within unified models (Alamu et al., 2023; Kang et al., 2025). Such integration will help translate farmer-generated evidence into biologically interpretable parameters, strengthening the connection between decentralized on-farm testing and formal breeding decision-making.